Redis学习笔记
本文是在阅读 JavaGuide 关于 Redis 的内容后做的个人整理;
核心知识点
可以看这篇文章的总结:https://juejin.cn/post/7525640395234230326#heading-4
基本数据类型8种
基本的5种
- String(字符串),使用SDS,即Redis自己构建的简单动态字符串来实现;
- List(列表),用的是双向链表,支持反向查找,可以用于实现消息队列;
- Hash(散列),键的值是键值对,可以用于存储对象,实现类似Java的HashMap;
- Set(集合),无序结构且无重复,支持交并差集的运算,可用于共同关注、粉丝等功能;用整数集合或哈希表实现(元素为整数且数量较少时用Set)
- Zset(有序集合),跳表实现,针对Set中每个元素增加一个权重参数score,根据这个参数有序排列;可以根据score范围获取元素列表,可以用于实现排行榜
特殊的3种
- Bitmap (位图)
- HyperLogLog(基数统计)
- Geospatial (地理位置)
底层数据类型8种
1. 简单动态字符串SDS
1 | struct __attribute__ ((__packed__)) sdshdr8 { |
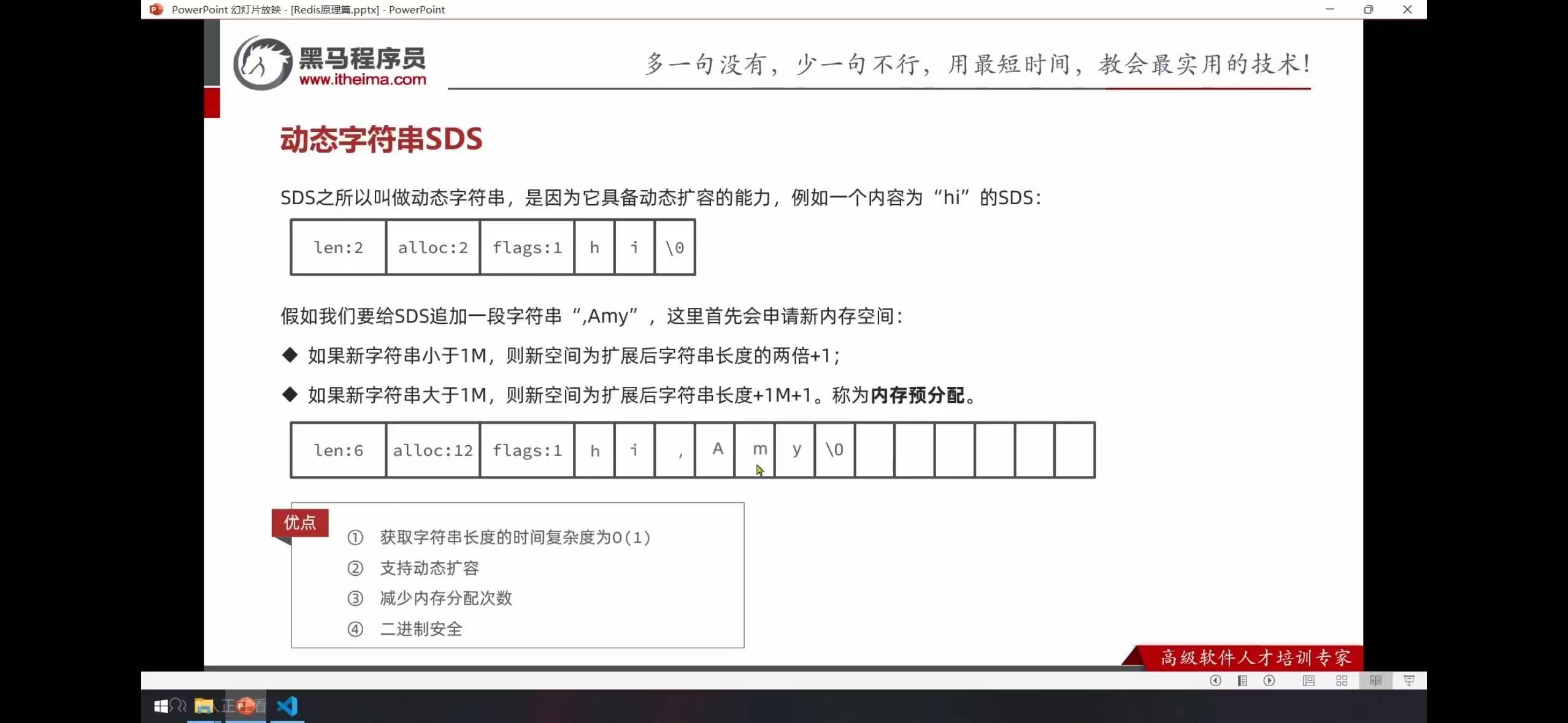
SDS 重点看四部分:len(已使用长度)、alloc(总分配空间)、flags(标识 sds 类型)以及 buf[](真实字符内容)。buf[] 末尾会额外追加 \0,以兼容 C 字符串接口。
sdshdr8/16/32/64 后面的数字,主要表示 len 和 alloc 的位宽;sdshdr5 是一个特例,它没有 len 和 alloc 字段,而是把长度信息压到 flags 这个 char 的高 5 位中;低 3 位仍然用于标识自己的 sds 类型。所以源码注释里的 5 unused bits,在 sdshdr5 上并不是真的“unused”。
动态扩容采用预分配策略:新字符串长度小于 1MB 时,通常按翻倍扩容;大于 1MB 时,则额外增加 1MB。扩容时可能发生类型升级,例如 sdshdr5 很容易变成 sdshdr8,但不会自动降级。
常见函数有:创建(_sdsnewlen,会自动选择类型)、扩容(_sdsMakeRoomFor)、追加(sdscatlen)和分割(sdssplitlen)。
2. Dict(哈希表/字典)
Redis 是一个键值型(Key-Value Pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过 Dict 来实现的。
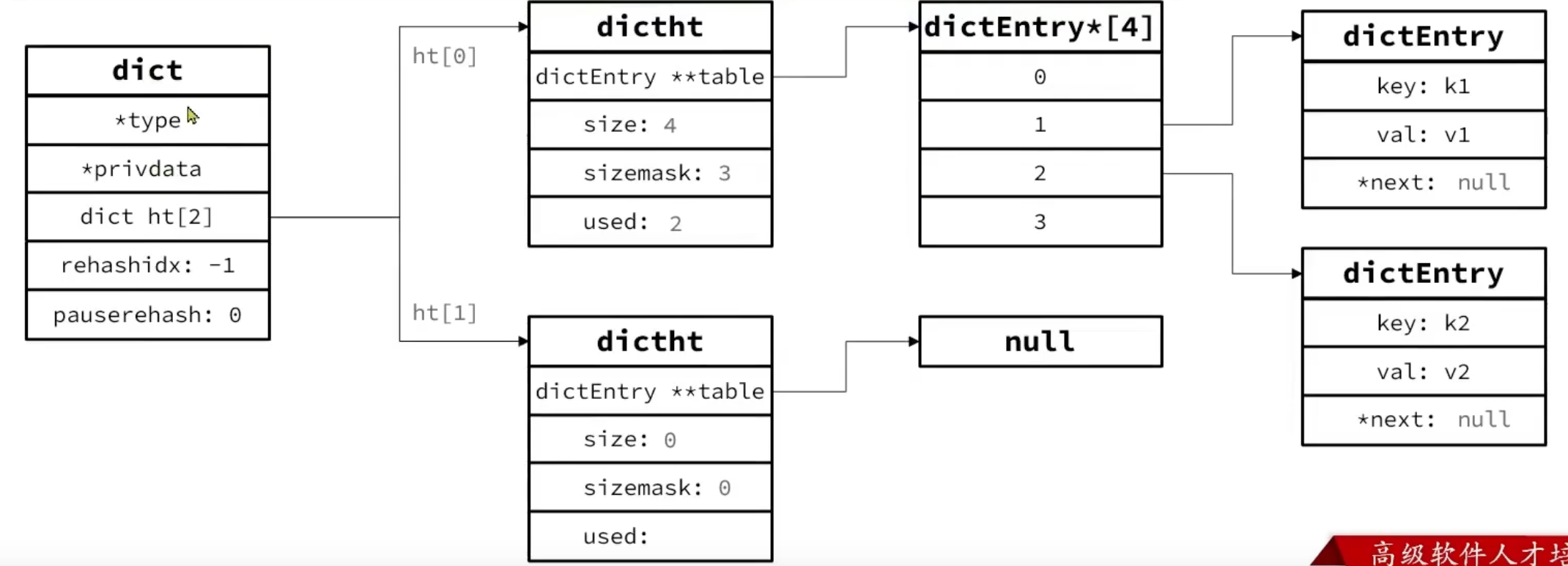
Dict 可以先按三层来理解:哈希表、哈希节点(dictEntry)和最外层的字典对象(dict)。文中的图偏旧版本实现,但不影响理解整体思路。

dict 里的 dictType *type 用来封装不同场景下的哈希函数和辅助逻辑;void *privdata 也是给这些场景做配套用的。
这里的 used 可能大于 size,因为多个元素可能映射到同一个桶,冲突时会通过 dictEntry 里的 *next 指针串成链表。
- 添加键值对的哈希槽运算(这个和jdk的
HashMap是一样的)
根据 key 计算出 hash 值 h,再用 h & sizemask 计算元素该落到哪个索引位置。这里可以用 & 代替取余,是因为 size = 2^n、sizemask = 2^n - 1,于是有:$a % 2^n = a & (2^n - 1)$。
- 哈希冲突时的头插法

上图中先插入 <k1,v1>,再插入 <k2,v2>。如果这两个键发生哈希冲突,<k2,v2> 会直接头插到 <k1,v1> 前面,这样就不需要每次都遍历到链表末尾。
再看这个 **table,它本质上指向的是 dictEntry 指针数组。新版本里这个表示方式做过调整,但理解成“哈希桶数组里放的是链表头指针”就够了。
- 为了支持 rehash,Dict 会同时维护两个哈希表。下图是一个旧版本的数据结构示意,此时第二个哈希表还是空的。
rehash

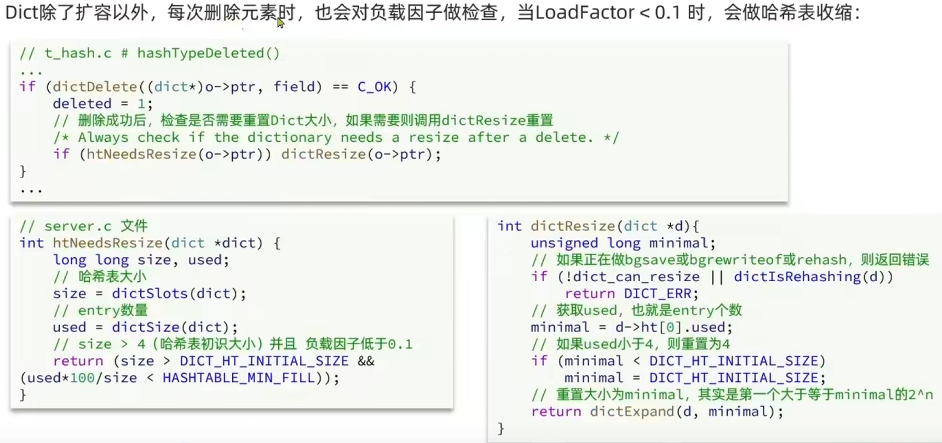
上面几个代码部分浅看一下就行,不用都看得非常明白,关键是要知道扩容和收缩的条件
下面是关键的rehash操作
渐进式 rehash:设置 dict.rehashidx = 0,表示开始 rehash。
将 dict.ht[0] 中的每一个 dictEntry 都 rehash 到 dict.ht[1],将 dict.ht[1] 赋值给 dict.ht[0],给 dict.ht[1] 初始化为空哈希表,释放原来的 dict.ht[0] 的内存(这样会造成主进程阻塞,不可取)- 每次执行新增、查询、修改、删除时,都会顺带检查
dict.rehashidx是否大于-1;如果是,就把dict.ht[0].table[rehashidx]上的链表迁移到dict.ht[1],然后将rehashidx++。
直到 dict.ht[0] 的数据全部迁移到 dict.ht[1](判断依据是 rehashidx >= ht[0].size),再把 rehashidx 设回 -1,表示 rehash 结束。
在 rehash 过程中,新增操作会直接写入 ht[1];查询、修改和删除则会依次检查 ht[0] 和 ht[1]。这样 ht[0] 只会越来越空,最终完成迁移。
3. Intset(整数集合):紧凑地存储多个整数
Intset 用来紧凑地存储多个整数,特点是:元素唯一且有序、支持编码升级、查询时可用二分查找。
如果Set集合是整数,且数量不超过一定值,则会用整数集合存储。
1 | /* intset.h */ |
- 操作元素时的地址转换和计算
虽然数组头 contents 的声明类型是 int8_t[],但真实元素大小取决于 encoding,可能是 int16_t、int32_t 或 int64_t。因此读取元素时,必须结合编码做地址换算。
1 | /* intset.c */ |
所以获取元素时,本质上要做“首地址 + 下标 * 元素大小”的计算。源码里是通过类型转换来完成这件事的。

这个地址计算在源码中是用类型转换实现的:
1 | /* Return the value at pos, given an encoding. */ |
- 插入元素时维持有序结构(必须是升序)
插入时会调用 intsetSearch(intset *is, int64_t value, uint32_t *pos) 做二分查找,*pos 表示计算出来的插入位置;如果元素明显比当前最大值更大、或比最小值更小,还会直接走边界优化。
插入前还会先判断新元素是否需要触发编码升级。如果需要升级,新元素一定只能放在首部或尾部;如果不需要升级,则继续二分搜索,找到就不插入,找不到就插到 pos,随后通过 intsetMoveTail(...) 整体搬移尾部元素。
- 编码升级:
intset *intsetUpgradeAndAdd(intset *is, int64_t value)
编码升级时会采用 back-to-front 的方式,也就是从后往前设置元素。
新加入的 value 一定是新的最小值或最大值,否则就没有必要升级编码。若 value 为负,它会落到最左边;若为正,则落到最右边。移动旧元素时,也会据此决定是否整体再右移一个位置。
这里有个插入元素和编码升级的示例:

4. LinkedList(双向链表)
5. SkipList(跳跃表):用于Sorted Set
6. ZipList(压缩列表)
7. QuickList(快速列表)
8. ListPack
9. RedisObject
缓存读写策略
旁路缓存模式
Cache Aside Pattern,最常见的一种。
读:先读缓存,未命中再读 DB,并把结果写回缓存;
写:先写 DB,再删除缓存。
- 无论“先删缓存还是先写 DB”,理论上都可能出现短暂不一致;实践里更常见的是“先写 DB,再删缓存”。
- 这种模式更适合读多写少的场景;如果写很多,缓存会频繁失效。
读写穿透模式
Read/Write Through Pattern,可以理解为由缓存层统一代理对底层数据库的读写。
读:先读缓存,未命中时由缓存层把数据从 DB 加载到缓存,再返回结果;
写:应用只与缓存层交互,由缓存层负责更新缓存并同步到底层 DB。
异步缓存写入
Write Behind Pattern,不常用,和读写穿透类似,但写入 DB 是异步完成的。
- 读:和读写穿透模式类似;
- 写:先写缓存,再由缓存层异步刷新到 DB。
持久化机制
Redis 常见的持久化方式可以概括为 RDB、AOF 和混合持久化。持久化的目的主要有两个:一是重启或故障后恢复数据,二是做数据同步。
RDB(快照, snapshotting)
- 作用:通过创建快照拿到内存数据在某个时间点上的副本;
- 用途:既可以用于恢复数据,也可以把快照复制到其他服务器上做数据同步;
- 特点:可以阻塞主线程执行,也可以通过
fork子进程来完成。
AOF(只追加文件, append-only file)
大致流程:
- 先执行命令,再把命令写入 AOF 缓冲区;
- 通过
write系统调用写到内核缓冲区; - 使用
fsync系统调用,刷新系统内核缓冲区到磁盘中。
持久化方式(fsync时机)
fsync 的时机可以配置为每次写都刷盘、每秒刷一次,或者交给 OS 自己决定。
AOF重写
当 AOF 文件过大时,会通过重写来缩小体积,这个过程通常由子进程完成。
重写期间会维护一个AOF 重写缓冲区,用于记录新 AOF 生成期间执行的命令;等重写完成后,再把这些增量命令补到新文件末尾。
混合持久化
RDB 和 AOF 一般会一起开启。
- RDB 是压缩后的二进制快照,文件小、恢复快,但快照之间可能丢更多数据;
- AOF 文件通常更大,但记录更细,数据安全性更高,实际丢失范围取决于
fsync策略。
事务
Redis 事务本质上是把命令放进一个队列中,然后按顺序依次执行。
某条命令执行失败时,后续命令通常仍会继续执行。
部署方式
主从复制 => 哨兵模式
- 主从复制:
优点:1. 主节点负责写,从节点负责读,读写分离可以提高性能;2. 数据有副本,具备一定容灾能力。
缺点:1. 主节点单点故障风险高,不具备真正的高可用;2. 主从同步存在延迟,一致性难以严格保证;3. 故障转移如果靠人工处理,成本较高。
- 引入哨兵:
监控 Redis 各个节点是否正常;
通知其他节点某个节点出现故障;
自动故障转移,把一个从节点提升为主节点,并让其他节点重新完成主从关系配置;
哨兵通常会部署多个节点(一般至少 3 个),通过投票选出 leader,因此哨兵本身也要高可用。
1 | // 配置文件 sentinel.conf |
1 | // 启动配置文件 |
切换过程中通常会有短暂不可用,但整体可用性已经比单纯主从复制高很多。
集群模式 Cluster
Cluster 主要解决的是单机容量和单机性能的上限问题。
如何添加新节点?节点之间会通过集群协议交换状态信息,并逐步完成握手和拓扑同步。
数据公平性
一共 16384 个槽位,每个主节点负责其中一部分;
数据读写时,会先对 key 做哈希计算,再映射到某个槽位,由负责该槽位的节点处理;
如果请求到了错误的节点,节点会把正确的槽号、IP 和端口返回给客户端,让客户端重定向到目标节点。

Redisson
Redis 里可以用 SETNX key value 实现最朴素的分布式锁:只有 key 不存在时才会设置成功,因此多个进程同时抢锁时,只有一个会成功。
问题:如果加锁后服务宕机,锁可能永远无法释放;如果给锁设置过期时间,又可能在业务还没执行完时提前释放。
解决方案是Redisson分布式锁:
key 是锁名,value 是一个 Hash;Hash 的键是线程或进程标识,值是重入次数。如果还是同一个持有者再次加锁,就把重入次数加 1;
Watch Dog 机制会在锁还被当前持有者占用时定时续约,默认是每隔 10 秒把过期时间续到 30 秒;
加锁失败时,线程不会一直空转,而是等待锁释放后再重试;
释放锁时会先校验持有者身份;如果是重入锁,就先把重入次数减 1,只有减到 0 才真正删除锁并唤醒其他等待线程。
- Redisson获取锁的代码流程解读:
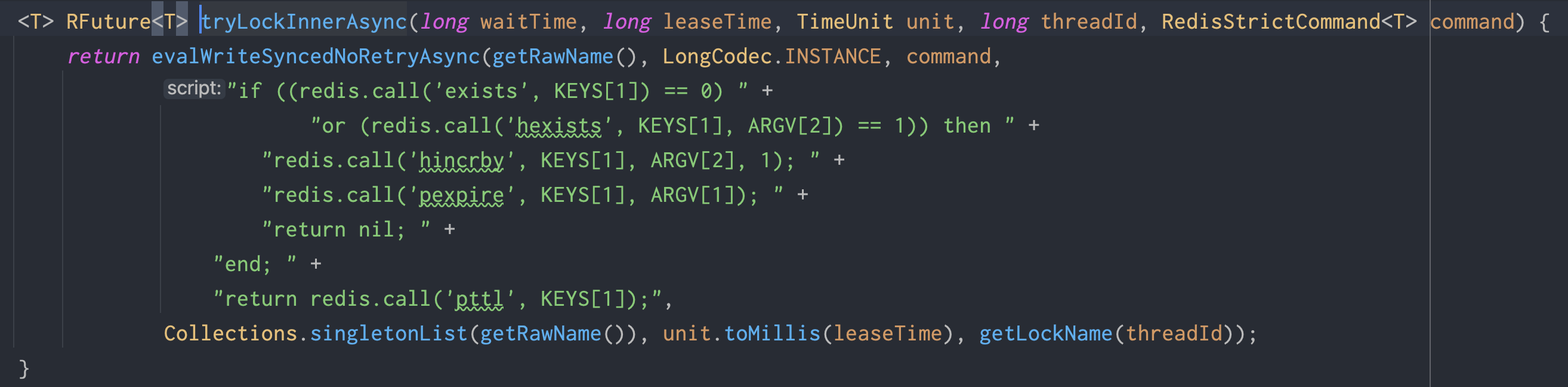
通过
tryLock发起加锁,请求里会带上waitTime和leaseTime:前者表示最多等多久,后者表示锁多久自动释放;tryLock内部会通过 Lua 脚本执行抢锁逻辑,用脚本保证这组 Redis 操作的原子性;如果锁不存在,就创建以锁名为 key 的 Hash,并写入当前持有者标识与重入次数 1;
如果锁已存在,则继续判断当前持有者是不是自己;是自己就做重入,不是自己就进入等待;
如果等待时间超过
waitTime,则返回加锁失败;当
leaseTime没有显式指定为固定值时,Redisson 会通过看门狗线程按周期续约。
- 尝试获取锁的代码:
- 续约的代码: