
Hadoop, Hive, Spark的关系详解
概念梳理
参考Gemini:https://g.co/gemini/share/749bc1f75063
1. Hadoop
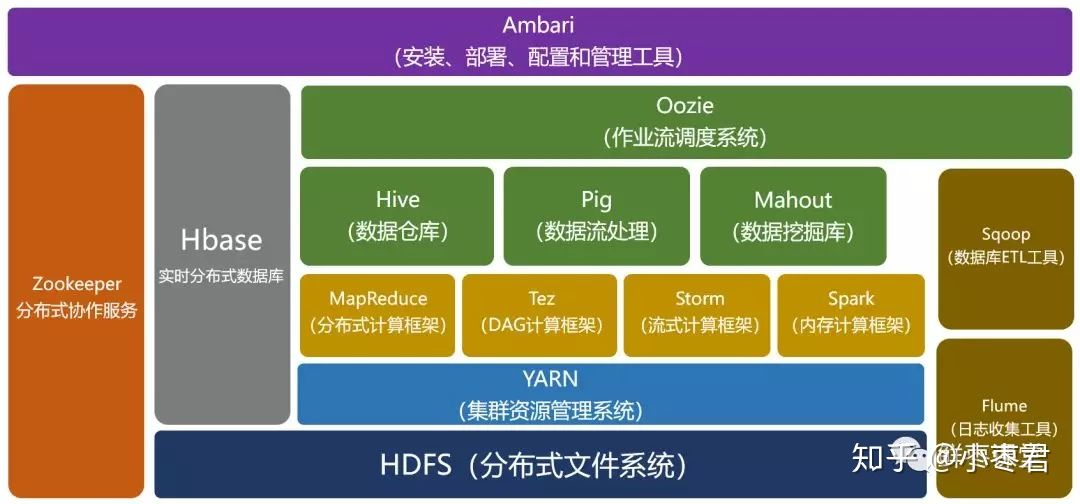
主要包含三部分:
1.1. HDFS
即Hadoop Distributed FileSystem分布式文件系统,将大文件分割成小块并分发到集群的多个节点上。用户存取数据都是和单机一样的操作流程,但实际上这些数据都是在多台单机上存储的,即屏蔽了底层的分布式实现。
1.2. MapReduce
单机之间的协同计算。Hadoop 早期主要的分布式计算模型,用于批处理任务。它将计算任务分解为 Map(映射)和 Reduce(规约)两个阶段。
MapReduce程序的代码比较复杂,需要自行编写,非常麻烦。因此出现了Hive和Pig等工具,而后续Hadoop的MapReduce部分就基本不用了,更多用的是它的HDFS文件系统。
1.3. YARN
即ResourceManager,资源管理器。负责集群资源的调度和管理,包括 CPU、内存等。它使得不同的应用程序(如 MapReduce、Spark、Hive 等)可以共享同一个 Hadoop 集群的资源。
这个感觉不一定要划分为Hadoop的组件。
2. Hive
https://github.com/apache/hive
构建于Hadoop之上,允许用户将 HDFS 中的非结构化或半结构化数据视为关系型数据库中的表,并允许直接使用 SQL 语句来查询和分析 HDFS 中的数据,而无需编写复杂的 MapReduce 代码。
Hive为了能将HiveSQL转化成MapReduce程序,需要知道数据的切分格式,如行列分隔符、存储类型、是否压缩、数据的存储地址等信息,这些被存储成一张表,称为元数据,即metastore。Hive不提供存储功能,因此需要额外的数据库存储,例如MySQL, PostgreSQL等等。
Docker镜像
bde2020/hive-metastore-postgresql:2.3.0就是用来postgresql来存储hive的metastore,然后在上层再构建一个metastore服务来给Hive使用;hive的metastore不仅能给hive自身使用,还能够提供给PrestoDB这个查询引擎来使用,也能提供给spark来使用(这就是spark on hive的解决方案)。参考后续的实例分析。Hive不仅可以把HiveQL转换为MapReduce任务,也可以转换为Spark任务,即采用Spark作为Hive底层的计算引擎。而且如今Spark更常见,因为它比MapReduce的速度快非常多。
3. Spark
https://github.com/lyhue1991/eat_pyspark_in_10_days
Spark的适用性非常广,有很多东西,发展成了一个生态群:spark sql, spark core, spark mllib, sparkR, spark Graphx等等
Spark既可以独立运行,也可以基于Hadoop或Hive运行,因为Spark适配性很强,什么代码都写了。
3.1. Hive on Spark
仍然是接收HiveQL,但是Hive底层不再将HiveQL转化成MapReduce任务,而是转化为Spark任务来加快计算。此时Hive的metastore仍被Hive自身使用,但使用 Spark 作为其底层计算引擎。
Hive on Spark现在是Hive组件(从Hive1.1 release之后)的一部分。
3.2. Spark on Hive
或者可以说是Spark with Hive Metastore:Spark自身也提供SparkSQL,可以通过访问Hive的metastore来无缝地查询hive定义的表。或者也可以说是SparkSQL取代了Hive的查询引擎这一部分。
4. Presto
Presto本身不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。MySQL首先是一个单点关系型数据库,其具有存储和计算分析能力,而Presto只有计算分析能力;在数据量方面,MySQL不能满足当前大数据量的分析需求,Hive是一个数据仓库,只能访问hdfs的数据;Presto是一个交互式查询引擎,可以在很短的时间内返回查询结果。
集群搭建
未完待续




