
JVM内存区域
总览
谈 JVM 内存区域时,最好先区分两个视角:
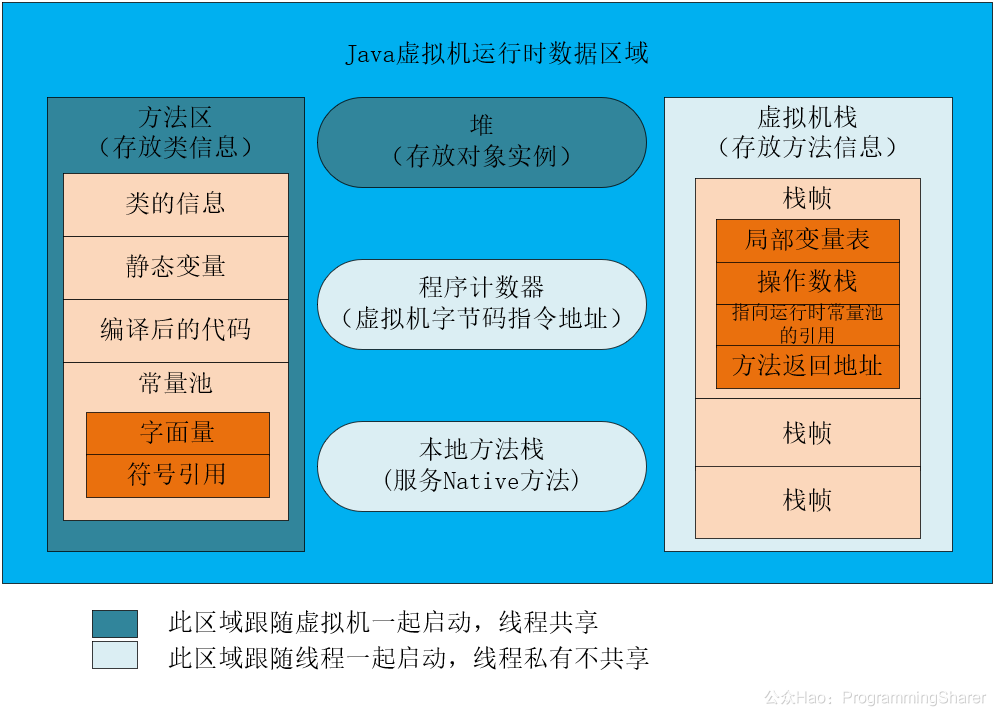
- JVM 规范视角:关注的是运行时数据区有哪些逻辑区域,包括程序计数器、虚拟机栈、本地方法栈、堆、方法区。
- HotSpot 实现视角:关注这些逻辑区域在具体虚拟机里是如何落地的。比如 JDK 8 之后,HotSpot 使用 元空间(Metaspace) 来实现方法区;元空间位于 本地内存,而不是 Java 堆中。
因此,平时常说的“JVM 内存”,通常指的是 JVM 运行时会使用到的内存区域;但如果继续深挖,就要分清楚哪些是 规范定义的逻辑区域,哪些是 HotSpot 的具体实现。
可以先用一张表把关系理顺:
| 区域 | 线程私有 / 共享 | 是否属于 JVM 规范中的运行时数据区 | 说明 |
|---|---|---|---|
| 程序计数器 | 线程私有 | 是 | 记录当前线程下一条将执行的字节码指令地址 |
| Java 虚拟机栈 | 线程私有 | 是 | 保存 Java 方法调用对应的栈帧 |
| 本地方法栈 | 线程私有 | 是 | 为 Native 方法服务 |
| 堆 | 线程共享 | 是 | 存放对象实例的主要区域,也是 GC 的核心区域 |
| 方法区 | 线程共享 | 是 | 存放类元信息、运行时常量池等 |
| 元空间 | 线程共享 | 不是独立逻辑区域 | HotSpot 中方法区的一种实现,位于本地内存 |
| 直接内存 | 线程共享 | 否 | 堆外内存,常用于 NIO |
线程私有区域
程序计数器
程序计数器(Program Counter Register)可以理解为 当前线程下一条字节码指令的地址指示器,或者说“字节码的行号指示器”。
它的核心作用有两个:
- 控制程序执行流程:顺序执行、分支、循环、异常处理,最终都依赖程序计数器来定位下一条指令。
- 支持线程切换后恢复执行位置:因为 Java 线程是轮流占用 CPU 的,所以每个线程都需要有自己的程序计数器,才能在线程恢复时继续从上次的位置执行。
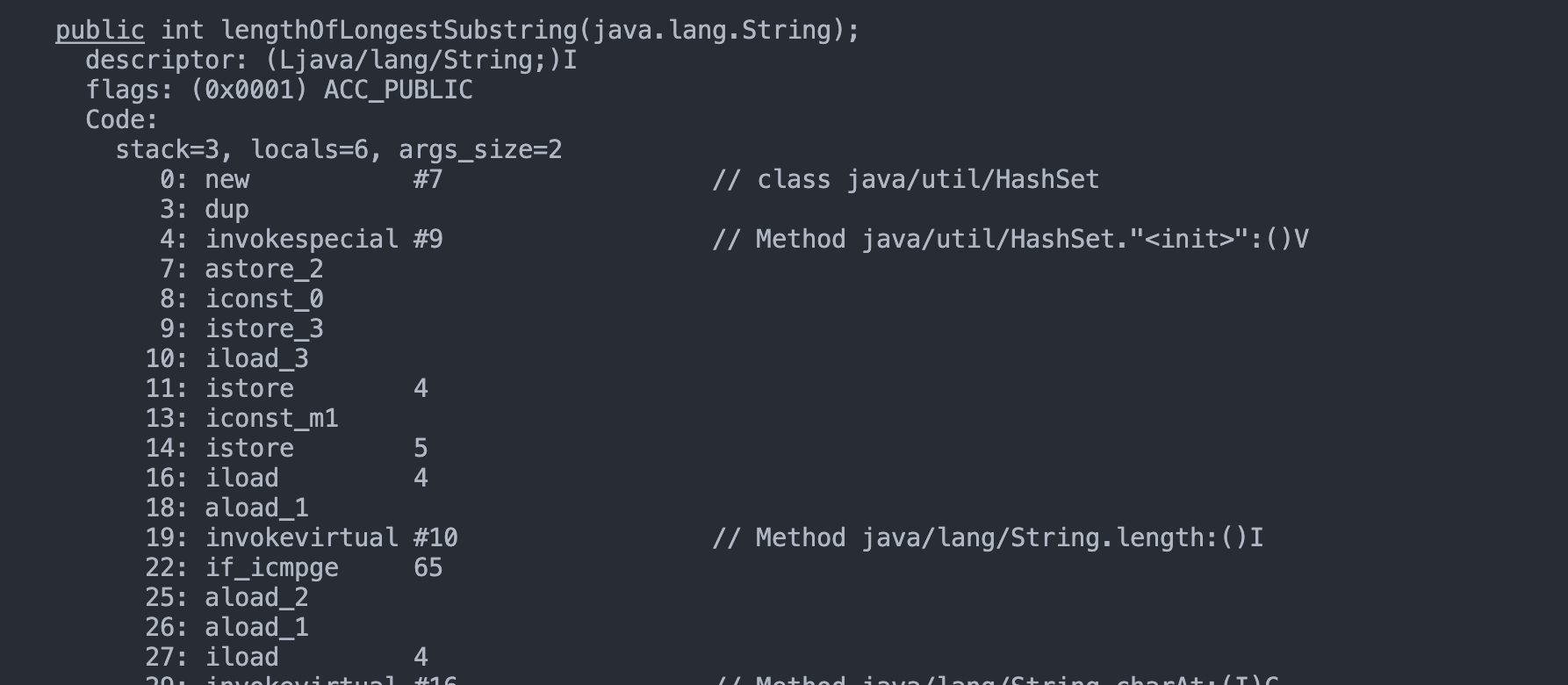
可以通过下面的命令查看字节码:
1 | javac ClassName.java |
请注意:
- 如果线程正在执行的是 Java 方法,程序计数器记录的是正在执行的字节码指令地址。
- 如果线程正在执行的是 Native 方法,程序计数器的值是 未定义 的。
虚拟机栈
Java 虚拟机栈描述的是 Java 方法执行的线程内存模型。每次方法调用时,都会创建一个对应的 栈帧(Stack Frame) 并压入虚拟机栈;方法执行结束后,栈帧出栈。
一个栈帧通常包含以下几部分:
1. 局部变量表
局部变量表是一个以 Slot 为单位的线性表,保存方法参数和局部变量。
它有几个关键点:
- 对于实例方法,索引为
0的位置通常保存的是this引用。 - 方法参数会按顺序放入局部变量表。
long和double占用 2 个 Slot,其他基本类型和对象引用通常占用 1 个 Slot。- 局部变量在编译期就已经确定了在局部变量表中的位置和所占 Slot 数。
2. 操作数栈
操作数栈用于保存方法执行过程中的中间结果,也是字节码指令直接操作的工作区。
例如下面这段代码:
1 | public int add(int x, int y) { |
对应的字节码大致如下:
1 | 0: aload_0 // 压入 this |
可以看到,方法调用本身也是通过操作数栈来完成参数传递和结果接收的。
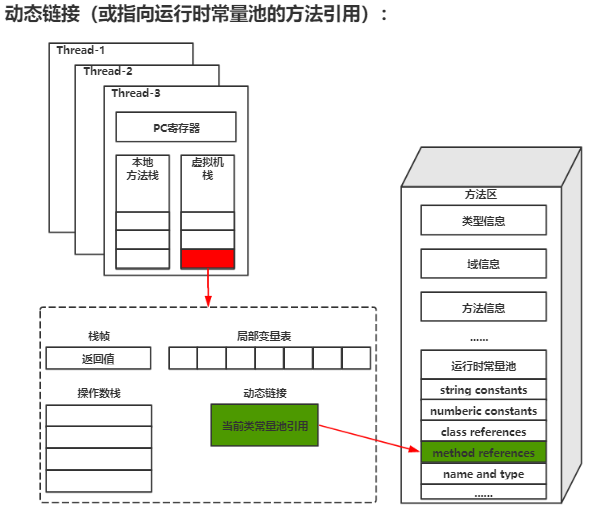
3. 动态链接
每个栈帧都会持有一个指向 运行时常量池 的引用,用于支持当前方法中的方法调用、字段访问等操作。
编译阶段,字节码里保存的往往只是 符号引用;运行阶段,虚拟机会把这些符号引用解析为可直接定位目标的引用信息,这就是动态链接要解决的问题。
例如执行 invokevirtual、invokestatic 等指令时,JVM 会根据符号引用找到实际要调用的方法。对于虚方法调用,最终调用哪个实现,还要结合对象的实际运行时类型决定,这也是多态实现的基础之一。
4. 方法返回地址
当一个方法被调用时,调用方需要知道:被调方法执行完以后,程序应该回到哪里继续执行。
这个“返回到哪一条指令继续执行”的位置,就是方法返回地址。
Java 方法退出有两种方式:
- 正常返回:执行到
return指令。 - 异常返回:方法执行过程中抛出了异常。
无论哪种方式,只要方法结束,对应的栈帧都会出栈,控制权回到调用方。
5. 可能出现的异常
虚拟机栈相关的常见异常有两个:
- **
StackOverflowError**:线程请求的栈深度大于虚拟机允许的深度。 - **
OutOfMemoryError**:如果虚拟机栈支持动态扩展,扩展时无法申请到足够内存,就可能抛出该异常。
本地方法栈
本地方法栈和 Java 虚拟机栈很像,区别在于:
- Java 虚拟机栈 为 Java 方法服务;
- 本地方法栈 为 Native 方法服务。
在 HotSpot 虚拟机中,本地方法栈与 Java 虚拟机栈通常是 合并实现 的,所以很多资料会把它们放在一起讲。
线程共享区域
堆
堆(Heap)是 JVM 所管理内存中最大的一块,也是垃圾收集器管理的主要区域,因此也常被称为 GC 堆。
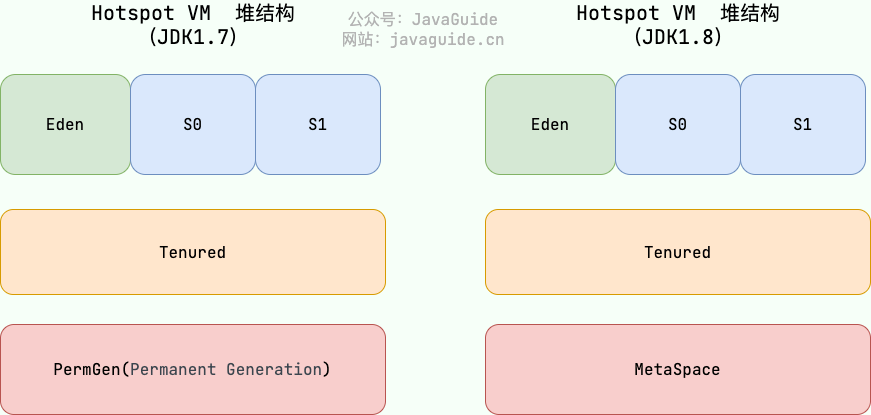
从垃圾回收的角度看,堆通常可以进一步划分为:新生代:Eden、Survivor From、Survivor To 和 老年代。
对象一般优先在 Eden 区分配。经过一次次 Minor GC 后仍然存活的对象,会在 Survivor 区之间来回复制,并逐渐增加年龄;当对象年龄达到阈值后,就会晋升到老年代。
分配和晋升
对象几乎都在堆中分配”,但 HotSpot 可能会使用 JIT 可能会结合 逃逸分析 做标量替换、栈上分配等优化,但这不是语言层面的保证,也不是所有对象都会发生。晋升的流程如下所示:
- 新对象通常先进入 Eden。
- 经过一次 Minor GC 之后仍存活的对象,会进入 Survivor 区,并且年龄加 1。
- 对象在 Survivor 区中每经历一次 Minor GC 且仍然存活,年龄都会继续增加。
- 当年龄达到阈值时,对象会晋升到老年代。这个阈值可以通过
-XX:MaxTenuringThreshold设置,HotSpot 中默认值通常不超过15。
除了固定阈值,HotSpot 还会根据 Survivor 区的占用情况进行 动态年龄判断。也就是说,对象不一定非要等到年龄达到最大阈值才进入老年代。
字符串常量池
字符串常量池的作用是 避免字符串字面量重复创建,从而减少内存开销。
需要区分两个版本变化:
- JDK 6 及以前:字符串常量池位于永久代。
- JDK 7 起:字符串常量池被移到了堆中。
之所以这样调整,核心原因是永久代回收效率偏低,而字符串又往往是高频、海量创建的数据。将字符串常量池放到堆中后,可以更自然地纳入常规 GC 管理。
方法区
方法区(Method Area)是 JVM 规范定义的一块 线程共享的逻辑区域,主要用于存储:
- 类的元信息;
- 运行时常量池;
- 字段和方法的描述信息;
- 静态变量;
- 即时编译后的一些相关数据。
要特别注意,方法区是规范概念,而永久代、元空间是 HotSpot 的实现方式,不能简单地把“方法区”和“元空间”画等号。
永久代和元空间
在 HotSpot 中:
- JDK 7 及以前,方法区通常由 永久代(PermGen) 实现;
- JDK 8 起,永久代被移除,改为使用 元空间(Metaspace) 实现方法区。
为什么要用元空间替代永久代?
- 永久代大小更容易成为瓶颈;
- 永久代会增加 GC 和参数调优的复杂度;
- 元空间使用本地内存,默认情况下更不容易因为类元数据膨胀而过早触顶。
如果需要限制元空间大小,可以使用:
1 | -XX:MaxMetaspaceSize |
运行时常量池
运行时常量池是方法区的一部分。class 文件编译完成后,里面会包含一张 常量池表,记录:
- 字面量(Literal),例如字符串、数字常量;
- 符号引用(Symbolic Reference),例如类名、字段名、方法名及描述符。
当类被加载后,这些信息会进入运行时常量池,供方法调用、字段访问、动态链接等过程使用。
下面是一个简单例子:
1 | public class HelloWorld { |
使用下面的命令可以看到常量池内容:
1 | javac HelloWorld.java |
输出中常见的常量池项包括:
1 | Constant pool: |
其中:
Methodref表示方法符号引用;Class表示类符号引用;NameAndType表示名称和描述符;Utf8常用于保存类名、方法名、字段名、描述符等字符串内容。
本地内存
严格来说,本地内存不属于 JVM 规范定义的运行时数据区,但 HotSpot 在实际运行过程中会大量使用它。
元空间
如果从 HotSpot 实现角度看,JDK 8 之后的方法区主要落在 元空间 中,而元空间使用的是 本地内存。所以:
- 从 规范视角 看,它讨论的是方法区;
- 从 HotSpot 实现视角 看,JDK 8 之后通常讨论的是元空间。
这两个概念相关,但并不完全等价。
直接内存 / 堆外内存
直接内存(Direct Memory)也叫堆外内存,不属于 JVM 规范中的运行时数据区。
它的特点是:Java 程序可以通过 NIO 等方式直接向这块内存申请空间,减少在 Java 堆和内核缓冲区之间的数据复制。
常见优点:
- 减少一次用户态与内核态之间的数据拷贝;
- 在高性能 I/O 场景下往往有更好的吞吐表现;
- 不直接占用 Java 堆空间。
常见代价:
- 分配和释放成本通常高于普通堆内存;
- 不受普通 Java 堆大小参数的直接约束,排查内存问题时更容易被忽略;
- 如果使用不当,可能出现堆外内存泄漏或内存占用过高的问题。
一般可以通过 ByteBuffer.allocateDirect() 来申请直接内存:
1 | ByteBuffer buffer = ByteBuffer.allocateDirect(1024); |
典型使用场景包括:
- NIO 文件读写;
- 网络通信;
- Netty 等高性能网络框架。
类加载和对象创建
类加载过程——222232
类从被加载到最终卸载,大致会经历:加载、链接(验证、准备、解析)、初始化、使用、卸载。
其中,链接(Linking) 又可以拆成:验证、准备、解析。
1. 加载(Loading)
这一阶段的目标,是把字节流形式的 .class 文件读入内存,并在 JVM 内部生成对应的类结构。
类加载器
站在现代 JDK 角度,常见类加载器包括:
- Bootstrap ClassLoader:负责加载核心类库,通常由 C/C++ 实现;
- Platform ClassLoader:JDK 9 之后用于加载平台相关类库;
- Application ClassLoader:负责加载应用 classpath 下的类。
如果你看到旧资料写的是 ExtClassLoader,那通常对应的是 JDK 8 及以前 的扩展类加载器。
双亲委派模型
类加载时,通常会先把加载请求向上委托给父加载器,只有父加载器无法完成加载时,子加载器才会尝试自己加载。它的核心价值是:
- 避免类的重复加载;
- 保证核心类库的唯一性和安全性。

补充一个细节:数组类不是通过类加载器直接“加载”出来的,而是由 JVM 在运行时按需生成;但数组类的元素类型,仍然会和对应的类加载过程有关。
2. 链接(Linking)
2.1 验证(Verification)
验证的目标是:确保字节流中的信息符合 JVM 规范,保证类在运行时不会危害虚拟机安全。
常见可以分为四类检查:
- 文件格式验证;
- 元数据验证;
- 字节码验证;
- 符号引用验证。
2.2 准备(Preparation)
准备阶段主要做两件事:
- 为类变量分配内存,如果是
static final且属于编译期可确定的常量,可能会在这一阶段就直接赋值。 - 为类变量设置零值。
从规范角度看,类变量属于方法区的一部分;从 HotSpot 的具体实现看,JDK 7 之后一些静态字段的存储方式与 Class 镜像对象有关,学习时最好把“规范定义”和“实现细节”分开理解。
2.3 解析(Resolution)
解析阶段的本质,是把常量池中的 符号引用 转换为可以直接定位目标的 直接引用。

这里容易和多态混淆,需要区分:
- 解析 解决的是“这个符号到底指向谁”;
- 动态分派 解决的是“虚方法调用时,本次到底执行哪个重写后的实现”。
例如:
- 对
invokestatic、invokespecial这类调用,目标方法往往可以较早确定; - 对
invokevirtual、invokeinterface这类虚调用,解析完成后,真正执行哪个方法,还要在运行时根据接收者的实际类型决定。
因此,多态的核心不只是“解析”,还包括运行时分派。
3. 初始化(Initialization)
初始化阶段会执行类的 <clinit>() 方法。这个方法并不是程序员手写的,而是编译器收集下面两部分内容后组合出来的:
- 静态变量赋值语句;
- 静态代码块。
并且,它们会按照 源码中的出现顺序 执行。
1 | public class MyClass { |
补充一点:JVM 会保证一个类的 <clinit>() 在并发场景下只会被正确执行一次,因此类初始化天然具备一定的线程安全语义。
4. 卸载(Unloading)
类卸载通常发生在 Full GC 过程中,而且条件比较苛刻。一般需要同时满足:
- 该类的所有实例都已经被回收;
- 加载该类的
ClassLoader已经被回收; - 对应的
Class对象没有被任何地方引用,无法再通过反射访问该类。
对象创建过程——54555
对象创建通常可以概括为以下几个步骤:
1. 类加载检查
执行 new 指令时,JVM 会先检查:
- 这个类是否已经被加载、验证、准备、解析和初始化;
- 如果没有,就先完成对应的类加载过程。
2. 分配内存
类加载完成后,对象大小就已经确定了,JVM 接下来会在堆中为对象分配一块连续内存。
常见分配方式有两种:
- 指针碰撞:适用于内存规整的场景;
- 空闲列表:适用于内存不规整的场景。
对象创建是高频操作,所以这里还会涉及并发安全问题。HotSpot 常见优化方式包括:
- TLAB(Thread Local Allocation Buffer):优先在每个线程私有的小块缓冲区中分配;
- CAS + 失败重试:在共享区域上进行原子更新。
3. 初始化零值
对象分配到的内存会先被初始化为零值,这样实例字段即使没有显式赋值,也能拿到语言规范要求的默认值。
4. 设置对象头
对象头通常包含两类信息:
- Mark Word:保存哈希码、GC 年龄、锁状态等运行时信息;
- Class Pointer:指向对象所属类的元数据。
如果是数组对象,还会额外记录数组长度等信息。
5. 执行 <init>() 方法
最后,JVM 会执行对象的实例初始化方法,也就是我们通常说的构造方法逻辑。到这一步,一个真正可用的对象才算创建完成。




